Tranquilidad, que todavía, las IAs no son las mejores entrenadoras de pokemons. Al menos, por los momentos. Sabemos que para mejorar, la práctica es imprescindible y los desarrolladores de chatbots como Claude o Gemini ponen en forma a sus IAs con juegos. Estos ponen a prueba su lógica y las obligan a saber navegar en mundos 3D.
Pokémon no es el primer juego utilizado como un gimnasio de las IA. Allá por el 2019 -que parece reciente, pero sabemos que la tecnología avanza a paso de gigante- Google Deepmind venció a dos jugadores profesionales de Starcraft 2 aplastándolos con 5 partidas a 0. Aunque, si nos retrotraemos más, a mediados del siglo pasado ya surgía esta idea de utilizar juegos para evaluar a las máquinas. En 1950, el matemático Claude Shannon lanzó una interesante propuesta en un ensayo académico. Proponía poner a las máquinas a jugar ajedrez. Setenta años después, se aplica esta dinámica y, actualmente, el juego más popular es Pokémon.


Claude, la IA streamer
Aunque sin ningún set-up con silla gamer y luces de neón de fondo, el agente de IA Claude, tiene su canal de Twitch donde hace streams de Pokemon Rojo por sí sola, o sea, sin intervención humana. En él podemos observar el juego y los procesos lógicos de esta IA. Para Anthropic, la creadora, es una forma de probar las habilidades de razonamiento, planificación y memoria de Claude en un entorno controlado pero complejo. Para los curiosos, nos sirve para ver sus «pensamientos» y qué tan cerca está de convertirse en un maestro Pokémon.
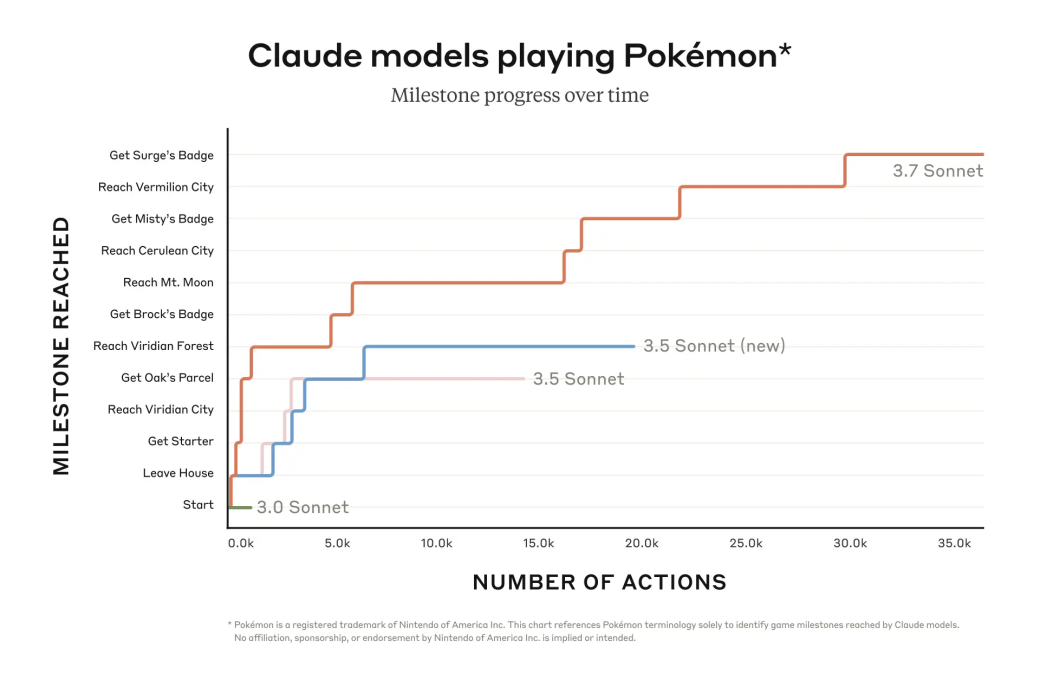
Son varios los modelos de Claude que han intentado ser el mejor entrenador Pokémon. Sonnet 3.0, Sonnet 3.5, Sonnet 3.5(new) han participado en el juego y el que está transmitiendo en directo es su último modelo lanzado hasta la fecha, Claude Opus 4. En la gráfica de abajo podemos observar cómo los tres primeros modelos han avanzado en las etapas del juego así como el número de acciones para llegar a esos checkpoints.
El número de acciones se refiere al número de número total de decisiones o movimientos realizados por el agente en el entorno. Mientras menos acciones necesite para una actividad, se puede entender que el modelo tiene facilidad para completar el objetivo o tarea.
Podemos ver en la tabla de abajo que, para llegar al «Bosque Verde» (Veridian Forest), una arbolada con pokemons de tipo bicho, a Sonnet 3.5 (new) le costó algo más de cinco mil acciones. En cambio, a Sonnet 3.7 menos de la mitad.
¿Por qué Pokemon Rojo?
De todos los juegos de Pokémon, ¿por qué Anthropic elige el Rojo para la Game Boy? Pokémon Rojo fue elegido por su naturaleza por turnos y su estructura lineal, lo que lo convierte en un campo de pruebas ideal para agentes de IA. Además, es un juego con gráficos sencillos que permite seguimiento más fácil.
Para ello equiparon al modelo de memoria básica, entrada de píxeles de pantalla y funciones para presionar botones y desplazarse por la interfaz, lo que le permite jugar de forma continua, superando los límites habituales de contexto. De esta manera, Claude puede mantener la jugabilidad durante decenas de miles de interacciones.

Aspectos positivos y negativos de entrenar a Claude con Pokémon
Anthropic hace balance de esta iniciativa. Claude demuestra su habilidad de tomar decisiones de manera autónoma, adaptarse a nuevas situaciones, memorizar y planificar estrategias a largo plazo para completar los objetivos del juego. Además, también manifiesta un clásico comportamiento humano, el ensayo y error. Es decir, analizar sus fallos y reajustar su plan para remediarlos.
Ahora bien, sí cabe tener en cuenta algunos aspectos condicionantes de entrenar a Claude con Pokemon. Por un lado, Pokemon no deja de ser un juego por turnos por lo que es más difícil evaluar su capacidad de respuesta rápida o más espontánea. Por otro lado, hay posibilidades de que su conocimiento previo sobre Pokemon influya, por lo que se puede cuestionar la autonomía total en sus decisiones.
Las IAs se echan unas partiditas, ¿un buen benchmark?
Además de Pokémon, se desempolvó Súper Mario Bros, concretamente el de 1985. Según informa TechCrunch, el laboratorio Hao Lab AI de la Universidad de San Diego sometió a varios agentes a jugarlo. Claude 3.7 fue la que mejor desempeño tuvo, seguida de Claude 3.5. y Gemini 1.5 Pro y GPT-4o sufrió la que más. El centro de investigación descubrió que los modelos de razonamiento como o1 de OpenAi tardan más en llegar a soluciones que los modelos «non-reasoning» a la hora de jugar a tiempo real, lo que se traduce en más tiempo para ejecutar. Y los hongos malvados del mundo de Mario no perdonan si no saltas a tiempo.
Los juegos llevan décadas usándose para entrenar máquinas, pero parte de la comunidad tecnológica no lo ve como el mejor criterio para evaluarlas o entrenarlas porque pueden verse limitadas por muchos factores que no se asemejan al mundo real (que es para lo que queremos las máquinas en primer lugar.) Eso sí, es evidente que poner a las IAs a jugar es un acto curioso y anecdótico que las acerca estas tecnologías complejas al gran público con estas tecnologías. ¿En un futuro veremos torneos de IAs gamers?
Si te ha gustado este artículo y quieres recibir más contenido sobre innovación y tecnología directamente en tu correo, suscríbete a nuestra newsletter y mantente siempre actualizado. No somos de los que llenan tu bandeja, solo compartimos los lunes.






