
El método habitual para enseñar a una inteligencia artificial o para entrenar robots consiste en emplear aprendizaje de refuerzo. Es decir, un entrenamiento que consiste en probar, equivocarse y obtener una respuesta positiva cuando consigue lograr el objetivo. Es algo que se lleva años utilizando también en animales y en humanos. Sin embargo, en el caso de máquinas e IA, la función de recompensa no es tan obvia como en un ser vivo.
Así, entrenar robots mediante aprendizaje de refuerzo da resultados, pero requiere de tiempo y esfuerzo. Además de ser complicado de escalar cuando la tarea a enseñar es compleja. Un reto de los investigadores es dar con maneras de entrenar una IA o una máquina cualquiera que sean más eficientes y extensibles. Como, por ejemplo, probar con la retroalimentación colaborativa. Es decir, con la colaboración colectiva de no expertos en el tema pero que han logrado realizar esa función para la que se está entrenando a una inteligencia artificial.


La solución a este problema la han encontrado un equipo de investigadores del Massachusetts Institute of Technology y de las universidades de Harvard y Washington. Este método para entrenar robots no se basa en una función de recompensa diseñada por expertos. En su lugar, aprovecha los comentarios de colaboración colectiva, a partir de muchos usuarios no expertos, para guiar a robot o IA a medida que aprende a alcanzar su objetivo.
Entrenar robots con ayuda de humanos
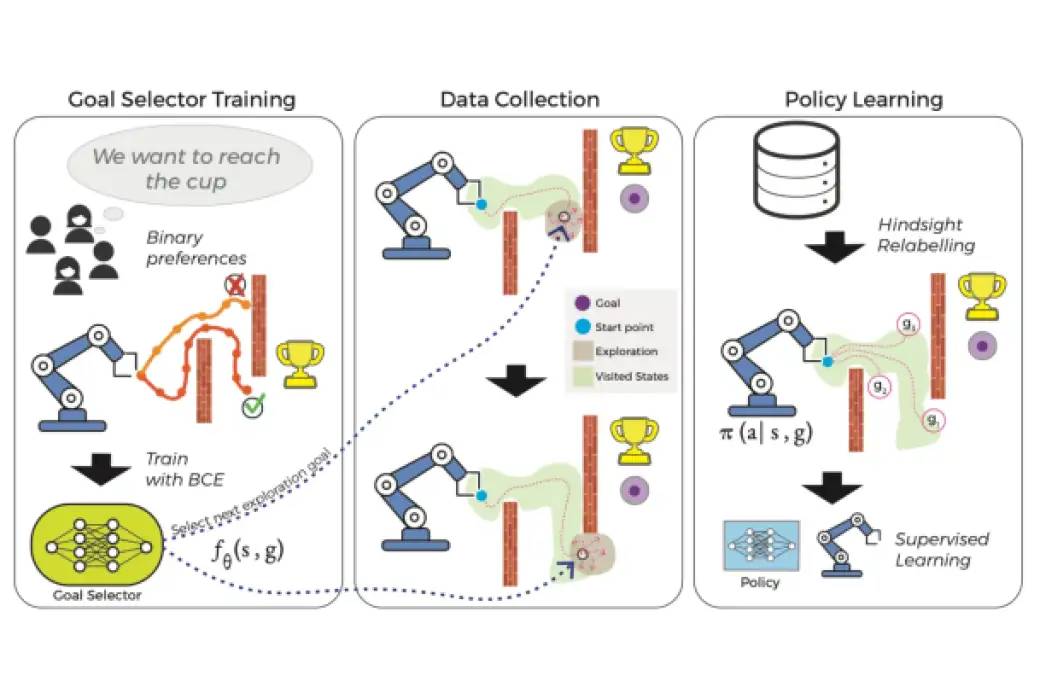
Según los investigadores, tal y como dicen en su estudio, disponible en arXiv: “los supervisores humanos pueden proporcionar una guía eficaz para dirigir el proceso de exploración, pero los métodos anteriores para aprovechar esta guía requieren una constante retroalimentación humana sincrónica de alta calidad, que es cara y poco práctica de obtener”. La técnica que han acuñado los investigadores se conoce por las siglas HuGE, Human Guided Exploration. En castellano, Exploración Guiada por Humanos.
En vez de entrenar robots empleando un complejo sistema de entrenamiento con ayuda de un experto, según este estudio, es más práctico “utilizar información de baja calidad de usuarios no expertos, que puede ser esporádica, asíncrona y ruidosa”. Así, la retroalimentación humana dirige la exploración. Y el aprendizaje autosupervisado a partir de los datos obtenidos genera unos resultados que sirven para que el robot cumpla con su propósito.
Si este sistema de entrenamiento se empleara en el futuro, podría ayudar a un robot a aprender a realizar tareas específicas. Por ejemplo, un robot doméstico que aprenda de su propietario sin que éste deba mostrarle al robot cómo se hace. El aprendizaje se realizaría como hemos visto: el robot exploraría por su cuenta y completaría esa información con comentarios humanos no expertos. Aprender de la colaboración colectiva. Incluso aunque el robot o inteligencia artificial hayan recibido instrucciones erróneas o imprecisas.
Entrenar robots e inteligencias artificiales no dista mucho del aprendizaje humano. De niños y adultos aprendemos de las instrucciones que recibimos, pero también de la observación. Y aprendemos tanto de lo que es correcto como de lo contrario. Humanos y robots no necesitamos que nos expliquen exactamente qué tenemos que hacer. Podemos aprenderlo observando el entorno en el que tiene que trabajar y con las instrucciones de otros que, saben o no, qué hay que hacer.
Aprender separando el ruido de la información
Así, los investigadores del MIT, Hardvard y Washington, explican sus aportaciones para entrenar robots de una manera más eficiente. La que más llama la atención, exploración guiada con comentarios humanos mínimos o ruidosos. Es decir, recibir datos sobre la tarea a realizar, aunque no toda ella sea correcta. Cantidad por encima de calidad. Esta primera aportación utiliza un algoritmo para separar o cribar los comentarios o feedback humano. En segundo lugar, este nuevo método de entrenamiento implica la capacidad de aprender de comentarios humanos no expertos en el tema o tarea en cuestión. Su solución permite aprender del feedback aunque sea “ruidoso, asíncrono e infrecuente”.
Para comprobar que la teoría era aplicable en el mundo real, los investigadores recrearon escenarios simulados y reales. En la simulación, usaron su sistema HuGE para aprender tareas de manera efectiva con largas secuencias de acciones, como apilar bloques en un orden particular o navegar por un laberinto grande. Y en las pruebas reales, entrenaron brazos robóticos para dibujar la letra «U» y elegir y colocar objetos. Para estas pruebas, usaron datos de 109 usuarios no expertos en 13 países diferentes de tres continentes.
Los resultados: consiguieron entrenar robots más rápido que con otros métodos. Además, vieron que con menos información, aunque fuera de no expertos, era más aprovechable que unas escuetas y exactas instrucciones. No solo eso. Con el método propuesto, los robots pueden aprender a realizar la tarea y luego restablecer el entorno de forma autónoma para continuar aprendiendo. Es decir, que podrían aprender a abrir una puerta y, al mismo tiempo, a cerrarla. Dos tareas aprendidas con un solo proceso de aprendizaje.






