
Beneath the web that we surf every day lies an enormous tangle of invisible websites that is bigger than we can even imagine: the Deep Web.
Recently, terms like proxy, anonymous browsing, VPN, Tor, etc. have started to pop up more frequently in conversations of normal everyday people. Usually, and for most of the time that the Internet has been around, the majority of web users have never concerned themselves with such things.
Average users just open their browser, search Google, and check their social networks. But with everything that’s come to light in recent years – government spying programs like PRISM, companies that provide services that just about all of us use and collect our personal information for sale to the highest bidder, censorship in different parts of the world and blocking citizen access to information in countries that are experiencing political crisis – people are becoming increasingly well-versed in the knowledge that they need to protect their identities, get around censorship, and discover other layers of the web.


Deep Web, the other Internet
Although it’s hard to believe, so much so that for many it’s just an urban legend, the Deep Web (Deepnet, Hidden web, Invisible web) makes up most of the Internet. The Deep Web refers to all of the content of the World Wide Web that doesn’t form part of the Surface Web, in other words, content that’s not in websites that can be indexed by search engines and that any user can access with a regular browser.
Few studies have been done, but one of the more recent ones by the University of California estimates that the Deep Web holds approximately 7.5 petabytes (1 petabyte is 1000 terabytes). According to similar studies, the web that we all know (Facebook, Wikipedia, blogs, etc.) accounts for less than 1% of the entire Internet.
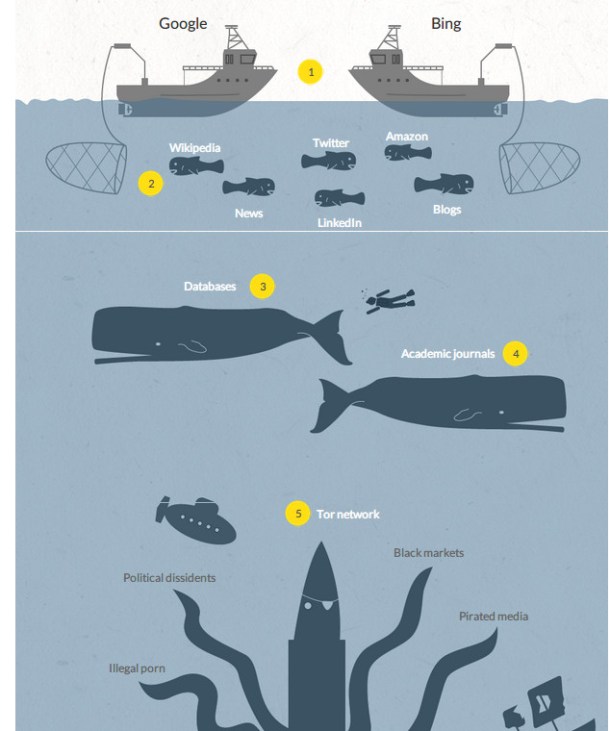
The idea is simple and confusing at the same time, but the web has been compared to the ocean. On the surface of the sea are the search engines, which collect the websites that are linked to each other, static pages, such as this blog, for example. This is the area of the ocean that we can “surf”. Databases are found a little deeper down. When a database is queried, it generates a unique page that is not indexed by search engines, and thus doesn’t form part of the Surface Web.
Academic publications, such as private scientific magazines, also don’t form part of the surface, because they are hidden in individual pages inside private networks, like the ones that the deceased Aaron Schwartz downloaded and for which he was arrested and put on trial. Lots of pages are also hidden because they form part of an Intranet, usually of companies or universities.
Tor
Descending even further, into the depths of this sea, we find the Tor network, the darkest part of the web. This is made up of a series of secret websites whose addresses end in .onion and that require specialised software to connect. This software is known as Tor. Lots of people use it to access the internet anonymously, because it encrypts all of the content that passes through it.
Tor is a network of virtual tunnels that protects users’ communications, bouncing them around inside an enormous network maintained by volunteers around the world. It was originally designed as a routing project of the U.S. Naval Research Laboratory in order to protect government communications.
The Deep Web isn’t a toy, and the darkness that surrounds it has made it the niche where the worst things imaginable are found: illegal drug traffic, pornography, arms, and even contract killers. They say that you don’t surf the Deep Web, you dive into it. Instead of search engines, it has a few reference sites where the search can begin, such as Hidden Wiki, but be very careful because you could run into things that you’d rather not see, or that others don’t want you to see.






