
Para los vehículos autónomos este hecho se vuelve crucial, por eso distinguir las actitudes de los viandantes es indispensable para ellos.
Predecir la intención de los peatones tiene como objetivo adivinar la siguiente acción de un peatón antes de que suceda. En los vehículos autónomos, esta capacidad para prever una acción es muy útil para mitigar el riesgo de un posible accidente.
Los conductores humanos son capaces de adivinar la intención extrapolando el movimiento pasado del peatón, y son capaces de reconocer acciones simplemente percibiendo cambios sutiles en la postura. Por ejemplo, la siguiente figura ilustra un escenario de tráfico urbano en el que una mujer (cuadro delimitador azul) se acerca a una carretera.


Dado un historial de observaciones visuales, la tarea de interés es predecir si la mujer tiene la intención de cruzar la calle o detenerse en el bordillo. Basándose en la experiencia y la extrapolación del pasado, un observador humano puede anticipar que es probable que se detenga en el bordillo. Esta decisión se basa en cambios sutiles de la persona observada. Incluso si el contexto de la escena no es visible, como se ilustra en los cuadros delimitados de la figura, un observador todavía puede inferir que es probable que se detenga basándose únicamente en los cambios sutiles en la secuencia de la postura.

Figura 1: La secuencia de arriba (izquierda-derecha) ilustra una escena de tráfico en el interior de la ciudad, donde una persona está cruzando la calle (cuadro delimitador amarillo) mientras que otra se detiene en el bordillo (cuadro delimitador azul). El método propuesto es capaz de inferir la intención un segundo antes de que el peatón llegue al bordillo (lo que, para un automóvil que viaja a 30 Km/h, se traduciría en una distancia de frenado de ocho metros). Los cuadros delimitadores ampliados se centran en los peatones sin el contexto del entorno.
Hoy en día, la capacidad de inferir la intención de los peatones se aproxima mediante una red neuronal profunda que predice la intención real de cada imagen de entrada de vídeo. El uso de redes neuronales es interesante gracias a su alto rendimiento en muchas tareas del mundo real, pero es especialmente desafiante para el caso de la intención de los peatones. Primero, requieren una gran cantidad de datos de aprendizaje anotados para un alto rendimiento, y la anotación de cada cuadro en una secuencia con etiquetas de intención es una tarea compleja y altamente subjetiva.
Como lo ilustran los cuadros delimitadores ampliados de la figura anterior, en función de un solo marco sin contexto o secuencia, las intenciones de cruzar y detenerse parecen igualmente probables en ambos marcos. Sin embargo, cuando se ve como una secuencia de imágenes, la verdadera intención se vuelve más clara. Por lo tanto, aunque solo se puede anotar un fragmento secuencial de marcos para la intención, definir la extensión temporal de este fragmento de marcos es una tarea muy subjetiva.
En segundo lugar, debido a la falta de conjuntos de datos suficientemente grandes para el reconocimiento de la intención, el entrenamiento se realiza principalmente con conjuntos de datos más pequeños. Este entrenamiento con pocos datos puede llevar el algoritmo a focalizarse sólo y exactamente en dichos datos, es decir, en la ejecución de la acción de unos pocos peatones. Así, se dificulta la adaptación a diferentes ejecuciones de la misma acción realizada por diferentes peatones.
El trabajo realizado por Ferran Diego, investigador del grupo científico de Telefónica, junto con investigadores de Robert Bosch GmbH y la Universidad de Heidelberg, presentado el año pasado en el IEEE Intelligent Vehicles Symposium celebrado en Changshu, China, propone un enfoque elegante e interesante para aprender a predecir la intención del peatón.

Específicamente, el objetivo principal es la integración de dicho enfoque dentro de un sistema de asistencia al conductor que frena automáticamente cuando se prevé que un peatón cruce la carretera. Dicho sistema solo es útil si es capaz de tomar decisiones en tiempo real mientras no consume recursos computacionales que pueden ser necesarios para otros componentes. Además, estas decisiones deben ser confiables y capaces de predecir la intención de cualquier ejecución de acción.
Sin embargo, como se mencionó, el principal inconveniente es el requisito de entrenar con un gran número de muestras. Para evitar la falta de grandes conjuntos de datos, los investigadores propusieron un nuevo esquema de entrenamiento y anotación (de supervisión débil) que solo requiere una única anotación por ejecución y, por lo tanto, aumenta el número de muestras de entrenamiento.
Básicamente, dado un conjunto de imágenes tomadas antes de que ocurra la acción, la red neuronal propuesta intenta predecir la intención futura lo más pronto posible (por ejemplo, un segundo antes de que ocurra). Primero, la red neuronal extrae una representación de la característica que describe los contenidos visuales del marco.
Normalmente, las intenciones y sus acciones asociadas pueden estar bien representadas por cualquier red neuronal estándar utilizada para visión artificial. Sin embargo, las características extraídas de estas redes funcionan para acciones que difieren mucho de las que nos interesan.
Por lo tanto, los investigadores se enfocaron en usar un descriptor de características visuales compacto basado en la postura humana. Este descriptor visual basado en posturas ayuda a identificar diferencias sutiles en los movimientos motores y, por lo tanto, codifica mejor la información sobre la intención de una persona.
Detectar esta intención solo desde una única postura es realmente ambiguo y, por lo tanto, los investigadores la manejan agregando la información temporal de los marcos anteriores con la información del marco actual para tomar la decisión final.
El entrenamiento de dicha red neuronal es trivial, dado un conjunto de datos con anotaciones de postura y anotaciones detalladas para todos los marcos en cualquiera de las secuencias. Sin embargo, no es el caso para la predicción de la intención, donde la postura humana se anota con la información temporal de la intención. Los investigadores abordan este problema mediante la disociación del problema en dos partes.
Primero, la representación de características se entrena en un conjunto de datos de entrenamiento de postura estándar y luego se usa como una inicialización para la red de intención general. Durante el entrenamiento, las capas del extractor de características de postura estándar pre-entrenadas reciben actualizaciones más pequeñas que las capas que agregan información temporal, y por lo tanto están ajustadas para el reconocimiento de la intención, por lo que aprenden características más relevantes y discriminatorias.
En segundo lugar, la falta de anotaciones de intención a nivel de trama se resuelve reformulando el problema como de supervisión débil, donde solo se proporciona una etiqueta de secuencia que refleja la intención en el paso del tiempo final, es decir, cuando realmente ocurre la acción.
Por lo tanto, esta optimización garantiza que no se hagan suposiciones cuando la intención comience a manifestarse, y por lo tanto evita cualquier sesgo que pueda introducirse debido al etiquetado subjetivo.
Los resultados de los experimentos demostraron que el enfoque propuesto conduce a una detección más temprana y más estable de la intención que otros enfoques existentes con operación en tiempo real. También demostraron la capacidad de detectar la intención un segundo antes de que el peatón llegue al bordillo, lo cual es crucial en escenarios como la conducción urbana autónoma.
Como se mencionó anteriormente, el contexto también desempeña un papel importante en el reconocimiento de la intención, y los investigadores tienen planteado estudiar la contribución de la información contextual en el modelo propuesto para un reconocimiento de la intención más sólido mientras se satisfacen las restricciones para integrarse en un sistema de asistencia al conductor.
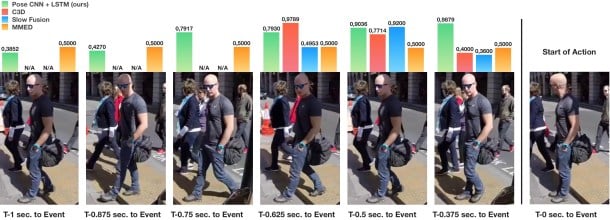
Figura 2: Variación en la probabilidad de que el peatón se detenga en una situación en la que realmente se detiene para nuestro método (barra verde) y los métodos de referencia seleccionados (barras roja, azul y amarilla).
Para los otros métodos, también se ve un retraso de tiempo inicial, asociado con la acumulación de la secuencia de vídeo, antes de que esté disponible una decisión del algoritmo.
REFERENCIA
O. Ghori, R. Mackowiak, M. Bautista, N. Beuter,L. Drumond, F. Diego & B. Ommer. Learning to Forecast Pedestrian Intention from Pose Dynamics. In Proc. of the IEEE Intelligent Vehicles Symposium. Changshu, China, 2018.






