
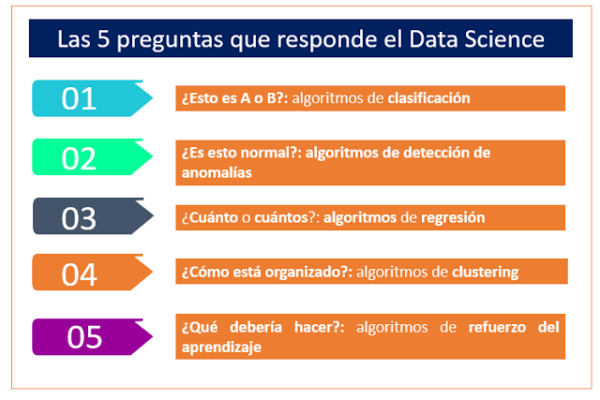
El mundo del Data Science puede llegar a ser extremadamente complejo pero, curiosamente, son sólo 5 las preguntas básicas a las que tiene que dar respuesta un científico de datos.
¿Y cómo encuentra estas respuestas?
El Data Scientist utiliza, por un lado, datos y, por otro, algoritmos. Si tuviéramos que explicarle a un profano en la materia en qué consiste el trabajo de un Data Scientist, podríamos decir que consiste en buscar respuestas a las siguientes preguntas:


- ¿Esto es A o B?
- ¿Es esto normal o aquí pasa algo raro?
- ¿Cuánto o cuántos?
- ¿Cómo está organizado esto?
- ¿Y ahora, qué conviene hacer?
Para ello, utiliza un “libro de cocina” con distintas recetas. Los ingredientes son los datos. Y las recetas, que nos dicen cómo preparar y combinar esos datos, serían los algoritmos.
A cada pregunta se corresponde una familia de algoritmos concreta. Vamos a verlos uno por uno.
¿Esto es A o B?
¿A o B?, ¿Si o No?, ¿peras o manzanas?…
Para responder a esta pregunta, el Data Scientist utiliza Algoritmos de clasificación. Pueden ser de clase 2, si sólo hay dos respuestas posibles (¿A o B?), o multiclase, en el caso de que existan más de dos respuestas posibles.
Sirve para responder preguntas como éstas:
- ¿Fallará esta pieza de maquinaria en los próximos días?
- ¿Qué atrae más clientes, un cupón regalo o un % de descuento?
- ¿Éste tweet es positivo?
- ¿Qué servicio elegirá este cliente A, B o C?
Por tanto, permite identificar a qué categoría pertenece la nueva información. Un ejemplo de estos algoritmos son los árboles de decisión.
¿Es esto normal o aquí pasa algo raro?
La siguiente pregunta a la que puede responder la ciencia de datos es si lo que estamos observando es normal o no. Para responder a esta pregunta, se usa una familia de algoritmos que se llama detección de anomalías.</strSirven para responder preguntas de este tipo:
• ¿Es normal este cargo de una tarjeta de crédito? (prevención de fraude)
• ¿Es normal este mensaje de correo? (prevención de spam)
• ¿Es normal esta medición registrada? (prevención de averías)
Estos algoritmos generan alertas sobre posibles eventos o comportamientos futuros que nos dan pistas muy útiles para evitar problemas. Por ejemplo, si una entidad financiera detecta un cargo por un volumen muy alto en una tarjeta donde no es habitual que haya este tipo de operaciones, se emite una alerta de posible fraude y se toman acciones para verificar la legitimidad de la operación.
También es posbile crear una alerta si la operación bancaria se realiza desde una ubicación que no coincide con la del móvil del cliente. Es decir, si el banco detecta que se va a realizar un cargo en Londres y tiene contratado un servicio como Smart Digits de LUCA, que detecta que el móvil del usuario está en Madrid, se genera una alerta para comprobar si se trata de un fraude o no.
¿Cuánto o cuántos?
La tercera pregunta a la que nos puede responder la ciencia de datos es ¿cuánto o cuántos? En éste caso, podemos usar Machine Learning para predecir la respuesta mediante la familia de algoritmos de regresión. Estos algoritmos permiten precedir el valor numérico que tendrá una variable, basándose en comportamientos anteriores.
Puede responder a preguntas como éstas:
- ¿Cuál será el volumen de ventas de este trimestre?
- ¿Qué temperatura hará mañana?
- ¿Cuál será el consumo eléctrico previsto a la hora del partido?
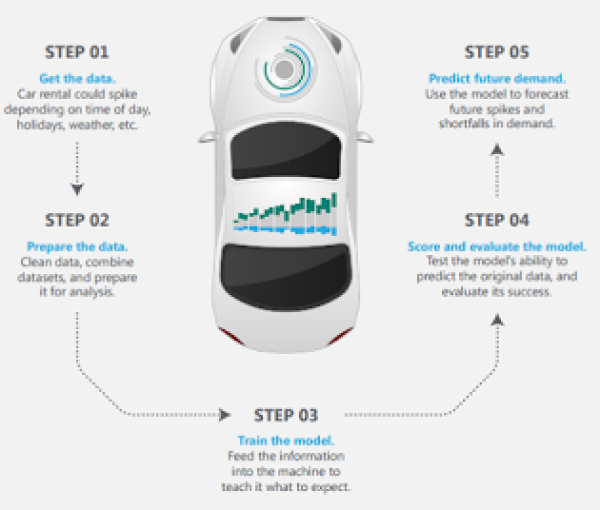
En la siguiente figura, podemos ver un ejemplo de cómo una empresa de coches de alquiler aplicaría un algoritmo de regresión para estimar la demanda sus servicios.
¿Cómo está organizado esto?
Las dos últimas preguntas son un poco más complejas. A veces, necesitamos comprender la estructura de los datos, saber cómo podrían organizarse. Una de las formas más habituales para sacar a la luz la estructura de los datos es agrupándolos en conjuntos de elementos similares en algún aspecto. Por ejemplo, los clientes de TV por cable pueden agruparse según el tipo de películas que les gustan.
También se pueden agrupar según criterios socio-económicos (edad, sexo, nivel de estudios, situación laboral, etc.). Por ello, cuando aplicamos técnicas de clustering, no hay una única respuesta correcta, sino varias que nos pueden aportar más o menos información de valor. Son muy útiles para realizar segmentaciones de clientes, predecir sus gustos o determinar un precio de mercado.
Permiten responder preguntas como éstas:
- ¿Qué modelos de impresora tienen la misma avería?
- ¿Qué libros debemos recomendar a este cliente?
- ¿Qué oferta personalizada debemos hacer a este cliente?
Si comprendemos cómo se estructuran los datos, podremos comprender y predecir comportamientos y eventos futuros.
Y ahora, ¿qué conviene hacer?
Para responder a esta última pregunta se usa la familia de algoritmos de aprendizaje por refuerzo. Se basan en los estudios sobre cómo fomentar el aprendizaje en humanos y ratas basándose en recompensas y castigos.
El algoritmo aprende observando el mundo que le rodea. Su información de entrada es el feedback o retroalimentación que obtiene del mundo exterior como respuesta a sus acciones. Por lo tanto, el sistema aprende a base de ensayo-error.
Estos algoritmos nos dan respuesta a preguntas que “se puede plantear” un robot o una máquina, como:
- Soy un coche sin conductor y esto es un semáforo en amarillo: ¿acelero o me paro?
- Soy un robot aspirador, y me queda un 30% de batería, ¿sigo aspirando o voy a la estación a recargar?
En resumen, la ciencia de datos nos puede dar respuesta a estas 5 preguntas básicas.
¿Dónde encaja la tuya?






