
Los sistemas de recomendación intentan predecir la siguiente acción de un usuario a partir de un historial de acciones previas. Por ejemplo, son los que, en base a lo que tú y otros usuarios como tú han comprado, te proponen algún producto interesante. O los que, después de ver esas dos series seguidas en la televisión, te aconsejan otra diferente que os podría gustar, a ti y a toda la familia.
Hoy en día, los sistemas de recomendación más potentes se basan en las llamadas redes neuronales profundas, algoritmos de aprendizaje automático que a base de procesar grandes volúmenes de datos pueden formarse una estadística precisa e informativa de dichos datos y las relaciones existentes entre ellos. Actualmente, uno de los principales problemas de las redes neuronales profundas, especialmente si están enfocadas a la recomendación, es el espacio que ocupan en la memoria física de las unidades donde trabajan. Esto dificulta su aprendizaje, lento e ineficiente, y su implantación en dispositivos con recursos de computación limitados, como, por ejemplo coches o móviles.
En un trabajo realizado por Joan Serrà, Alexandros Karatzoglou, y científicos del grupo de investigación de Telefónica; y presentado el pasado agosto en la conferencia internacional de sistemas de recomendación que se celebró en Como (Italia), se propone una solución muy interesante para optimizar el espacio ocupado por sistemas de recomendación basados en redes neuronales profundas: comprimir los datos antes y después de entrar y salir del sistema. Su observación principal se basa en que el volumen de estos sistemas está mayoritariamente condicionado por las capas que interaccionan directamente con los datos que conforman a la vez la entrada y la salida de los mismos. Así, una red neuronal de recomendación puede necesitar de una entrada y una salida formada por millones de números (tantos como productos haya en el catálogo del servicio que se ofrece), dedicando recursos a cada uno de esos números de entrada y salida. Además, las redes neuronales profundas necesitan leer y escribir este tipo de datos multitud de veces para aprender las relaciones existentes entre todos ellos.


Comprimir los datos en sí no sería un obstáculo si el resultado de dicha compresión no tuviera que ser usado para el entrenamiento de las redes de recomendación. La compresión que se aplique tiene que respetar la estructura estadística de la información (es decir, debe permitir el aprendizaje por parte de la red) y tiene que ser reversible (es decir, hay que poder descifrar rápidamente las recomendaciones producidas por la red). Además, debe contar con otras cualidades para el procesado de redes neuronales, como, por ejemplo, que se adapte bien a la función de coste o que sea rápida de ejecutar.
La idea que propusieron los investigadores fue usar lo que se llama un filtro de Bloom, y presentaron una metodología para adaptar su uso al entrenamiento de sistemas de recomendación basados en redes neuronales. En esencia, un filtro de Bloom es una estructura de datos probabilística muy compacta que permite comprobar eficientemente si un elemento (o producto) está presente en dicha estructura. De esta forma, codificados en un filtro de Bloom, se pueden suministrar datos de manera más eficiente a una red neuronal, y ésta, basándose en la teoría de los filtros de Bloom y explotando la metodología propuesta, puede aprender directamente sobre los datos codificados o comprimidos, sin necesidad de expandirlos o ni siquiera considerar si dimensión original.
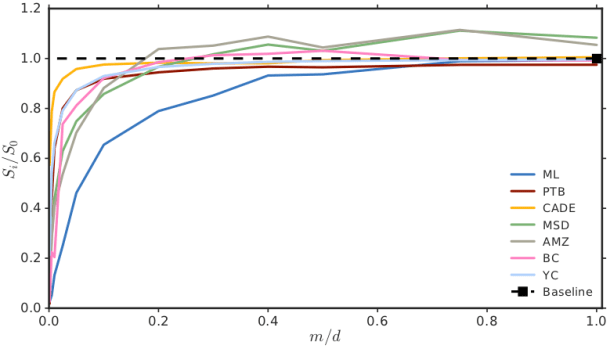
El resultado de los experimentos realizados por los investigadores fue que se puede entrenar redes de recomendación profundas hasta tres veces más rápido y cinco veces más compactas sin perjudicar su funcionamiento, y de manera que estas operen con una precisión comparable a la de las redes originales, mucho más grandes y lentas. No sólo esto, sino que se observó que en algunos casos (tres de las siete bases de datos consideradas en el estudio), la precisión de las redes de recomendación usando filtros de Bloom y la metodología propuesta podía llegar a ser hasta un 12% superior a la de las redes de recomendación originales. Todo ello sin requerir cambios estructurales en el modelo o en el tipo de entrenamiento, y sin ocupar espacio adicional de almacenamiento. En cierto sentido, es como si los sistemas de recomendación se pusieran en forma: con menos peso, ganando velocidad, ¡y con igual o mejores resultados!






