
Tecnologías disruptivas como la inteligencia artificial suelen protagonizar polémicas a medida que se integran en todos los ámbitos de nuestra sociedad. Una de las polémicas tiene que ver con la necesidad de entrenar los modelos de IA para que sean capaces de desempeñar tareas complejas. Para ello es necesario facilitarles una gran cantidad de información. Y si hablamos de redes sociales y aplicaciones mensajería, como Slack o Instagram (de Meta) la protección de datos se hace más necesaria que nunca.
De manera independiente, pero coincidiendo en el tiempo, usuarios de Meta y Slack han compartido en Internet que ambas compañías han elegido el camino fácil para entrenar sus modelos de inteligencia artificial. Tratándose de empresas que gestionan datos de millones de personas, información personal y profesional, es normal que la polémica esté servida. ¿Hasta qué punto puede una compañía como Meta o Slack hacer uso de los datos de sus usuarios para que sus inteligencias artificiales sean más inteligentes?


Expertos y profanos en el tema llevan tiempo criticando que los modelos de IA actuales generan contenido a partir de contenido que ya existe previamente. Contenido al que han tenido acceso a través de buscadores, páginas web o redes sociales. Pero a esa polémica se le añade la protección de datos personales. No es lo mismo entrenar una IA con contenido público compartido por su creador que conversaciones privadas.
Slack, inteligencia artificial y su política de privacidad
Slack es una popular aplicación de mensajería instantánea utilizada especialmente en el ámbito profesional. Pertenece al gigante empresarial Salesforce. Como ha ocurrido con otras herramientas profesionales, Slack ha ido introduciendo funciones en las que la inteligencia artificial tiene un gran peso. En concreto, en febrero de este año, Slack anunció que iba a utilizar funciones de IA generativa en su plataforma de productividad.
Esas funciones consisten en que Slack AI es capaz de responder preguntas y resumir lo más importante que se había escrito en un canal o en una conversación. En el anuncio, se recalcaban conceptos como seguridad y privacidad. “Se basan en la infraestructura segura y de confianza de Slack para que mantengas el control total de tus datos”. La parte importante venía al final del anuncio: “Slack no comparte datos de clientes con proveedores de LLM y no utiliza datos de clientes para entrenar modelos de lenguaje grandes (LLM)”. Por lo demás, el uso de Slack AI es de pago y va asociado a los planes Enterprise. Y en inglés.
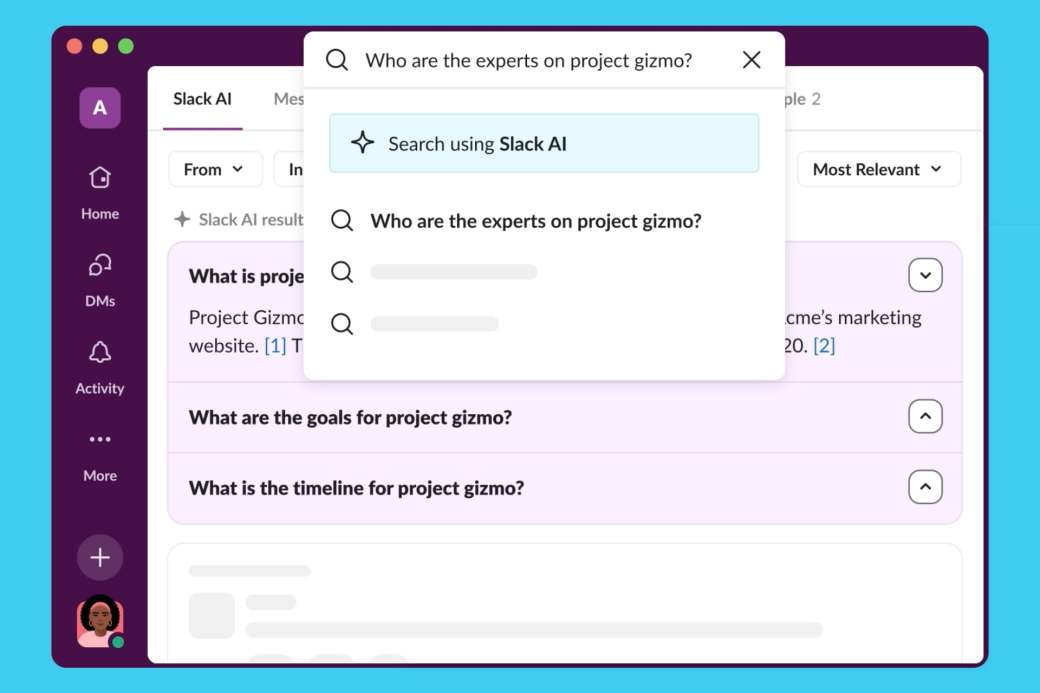
Sin embargo, en mayo, varios usuarios han criticado los principios de privacidad de Slack. Disponibles en inglés y en español. En concreto, el párrafo que dice que “para desarrollar modelos de IA (inteligencia artificial) / AA (aprendizaje automático) no generativos para ciertas funciones, como los emojis y las recomendaciones de canales, nuestros sistemas analizan los Datos de cliente (como mensajes, contenido o archivos que se hayan enviado en Slack), así como Otra información (entre la que se incluye la información de uso)”.
La respuesta de Slack a la polémica
Aunque los principios de privacidad de Slack dicen que “los datos no se filtrarán entre espacios de trabajo” o que “contamos con controles técnicos para evitar el acceso”, las quejas surgen especialmente porque, por defecto, todos los usuarios de Slack forman parte del entrenamiento de IA. Sin aviso previo. Y si quieres “abandonar”, debes contactar con Slack expresamente. Vía correo electrónico. Y de una manera que recuerda a tiempos pretéritos.
En respuesta a la polémica surgida en redes sociales, especialmente en Twitter (ahora X), Slack ha publicado dos artículos en su blog oficial. El primero titulado “Cómo construimos Slack AI para ser segura y privada”. Y el segundo, “Cómo protege Slack tus datos cuando usas el aprendizaje automático y la inteligencia artificial”. En el primero, Slack afirma que los datos de los clientes nunca abandonan Slack, que no se utilizan para entrenar modelos de lenguaje largos y que Slack AI solo utiliza los datos que el usuario puede ver. Algo que se contradice con los principios de privacidad, que son los que prevalecen legalmente.
El segundo artículo, precisamente, dice que esos principios fueron actualizados para ser más claros. Pero Slack se limita a hablar de estándares, privacidad y seguridad. Obviando, por un lado, que el acceso a archivos, mensajes y contenidos personales o profesionales es incompatible con la protección de datos. Y, lo que es peor, que los usuarios de Slack no fueron informados de ello. Es más. Quienes lo han descubierto, a través de Internet, ahora deben solicitar que sus datos no formen parte del entrenamiento de Slack AI mediante un proceso manual y poco transparente.
Meta y la privacidad de datos en Facebook e Instagram
Meta, antes Facebook, es el gigante de Internet que posee Facebook, Instagram y WhatsApp, tres de las redes sociales más populares. Desde hace años, trabaja en el desarrollo de su propio modelo de inteligencia artificial. De código abierto y disponibles para desarrolladores y otras empresas, Meta tiene varios modelos de IA, aunque el más popular es Llama 3.
Coincidiendo con la polémica de Slack, las críticas de muchos usuarios se han hecho oír en redes sociales respecto a la política de Meta y su IA en dos de sus aplicaciones estrella: Facebook e Instagram. Por el momento, no se ha mencionado WhatsApp. Estas críticas tienen que ver con el aviso que estamos recibiendo los usuarios europeos de Instagram y Facebook. El aviso advierte de un cambio en la política de privacidad de ambas redes sociales. Un cambio que se hará efectivo el 26 de junio. Y que afecta a publicaciones, fotos, pies de foto y mensajes enviados a la IA.
La parte más conflictiva es la que dice que, amparándose en “intereses legítimos”, usarán nuestra información para desarrollar y mejorar su modelo de inteligencia artificial. El aviso no se puede aceptar o rechazar. Simplemente leer y cerrar. Es decir, que Meta toma la decisión de entrenar su IA con los datos de sus millones de usuarios. Aunque tenemos “el derecho a oponernos”. Para ello, Meta ha creado dos formularios en el que debemos indicar nuestro país de residencia, dirección de correo electrónico y argumentar cómo nos afecta el tratamiento de esos datos. Los formularios dicen que “revisaremos las solicitudes de objeción de acuerdo con las leyes de protección de datos pertinentes. Si aceptamos tu solicitud, se aplicará a partir de ese momento”.
Está por ver si las autoridades europeas aceptan esta estrategia y si se ajusta a las recién creadas normativas de la UE sobre privacidad, protección de datos y buen uso de la inteligencia artificial. Mientras, los usuarios tendrán que valorar personalmente si quieren o no compartir sus datos con los modelos de IA de Meta.






