
En un negocio data-driven, cada problema es único, con sus propios objetivos, restricciones, aspiraciones etc. Sin embargo, para poder resolver estos problemas, la estrategia del Data Scientist es descomponer un problema complejo en diferentes sub-tareas más sencillas que ya sabemos resolver con distintos algoritmos de Machine Learning.
¿Cómo resolvemos los problemas las personas?
En un post anterior en el blog de LUCA vimos que el concepto básico que subyace bajo la idea de Inteligencia Artificial es conseguir que una computadora resuelva un problema de la misma forma en que lo haría una persona.


Hay muchas formas de intentar resolver un problema desde una perspectiva humana, pero, en concreto, dos preguntas nos son de gran ayuda cuando nos enfrentamos a una situación nueva.
La primera es:
¿Se parece este problema a alguno que haya resuelto ya antes?
Y la segunda:
¿Puedo descomponer este problema complejo en varios sub-problemas más sencillos?
Está claro que basarnos en la experiencia, en lo que hemos aprendido en circunstancias anteriores, nos puede ser de gran utilidad. No tiene sentido reinventar la rueda. Y, por otra parte, cuando un problema es complejo, pero se puede descomponer en distintas partes, es muy probable que ya sepamos cómo resolver muchas de ellas. Si sólo tenemos que trabajar la parte del problema que realmente es nueva para nosotros, ganaremos tiempo y seremos mucho más eficaces.
Cuando trabajamos con Aprendizaje Automático (Machine Learning, ML), en lugar de programar un código basado en unas reglas, lo que hacemos es trabajar con algoritmos y entrenarlos con datos. Algoritmos hay muchos, y complejos, casi todos, pero tampoco es imprescindible conocerlos uno a uno. Uno de los trabajos del Data Scientist es, precisamente, determinar cuál es el más adecuado para cada caso particular, aunque normalmente cada profesional tiene su propia «Caja de herramientas» con sus algoritmos favoritos, aquellos que le resuelven la mayoría de los problemas.
Sin embargo, las tareas que esos algoritmos nos van a permitir resolver, aquellas que nos podemos encontrar como sub-problemas en problemas más complejos, no son tantas.
Vamos a ver cuáles son las principales:
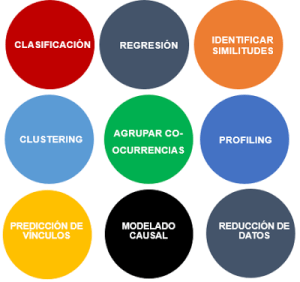
- Clasificación: una tarea de clasificación consiste en, dado un individuo, saber a qué clase pertenece, basándonos en lo que hemos “aprendido” de otros individuos. Por ejemplo:
¿Qué clientes de Telefónica estarán interesados en esta oferta?
Basándonos en la información del histórico de clientes, resumida en una serie de variables como puede ser la edad, estado civil, nivel de estudios, antigüedad como cliente etc., los algoritmos de clasificación construyen un modelo que nos permite asignar, a un nuevo cliente la etiqueta más adecuada entre estas dos: “Estará interesado” o “No estará interesado”. Los algoritmos de scoring son muy similares, pero más específicos. Nos dan la probabilidad de que un cliente esté interesado o no.
- Regresión: las tareas de regresión se utilizan cuando lo que se quiere averiguar es un valor numérico de una variable continua. Siguiendo con el ejemplo anterior, nos servirían para, basándonos en el histórico de consumo de los clientes, parametrizado según las variables anteriores (u otras que defina el Data Scientist), podamos responder a preguntas como ésta:
¿Cuál va a ser el consumo en … (voz, datos, etc.) de este cliente en un mes?
-
Identificar similitudes: se trata de identificar individuos “similares” según la información que tenemos de ellos. Es la base de los sistemas de recomendación, que te ofrecen distintos productos según los que hayas consultado o adquirido previamente.
-
Clustering: las tareas de clustering tienen que ver con agrupar individuos por su similitud, pero sin un propósito específico. Suele usarse en las fases de exploración preliminar de los datos, para ver si existe algún tipo de agrupamiento natural, que puede sugerir la mejor forma de analizar los datos. Por ejemplo, estas tareas nos darían respuesta a preguntas como:
¿Se puede clasificar a nuestros clientes en grupos o segmentos naturales?
¿Qué productos deberíamos desarrollar?
- Agrupar co-ocurrencias: esta tarea busca asociaciones entre “entidades” basadas en su coincidencia en transacciones. Por ejemplo, responderían a la pregunta:
¿Qué productos se suelen comprar juntos?
Mientras las técnicas de clustering buscan agrupar elementos, basándose atributos de éstos, la agrupación de co-ocurrencias se basa en que dichos elementos aparezcan juntos en una transacción. Por ejemplo, es habitual que una persona que compra una cámara de fotos, compre también una funda para la cámara, o una tarjeta de memoria.
Por ello, puede ser interesante hacer promociones de ambos productos a la vez. Sin embargo, a veces no son tan “evidentes” las coincidencias y por eso resulta muy interesante analizarlas.
- Profiling: cuando hablamos de Profiling, hablamos de comportamientos típicos. Estas técnicas buscan caracterizar el comportamiento esperado de un individuo, grupo o población. Se pueden plantear preguntas como:
¿Cuál es el consumo de móvil típico de este segmento de clientes?
La descripción de estos comportamientos “típicos” se suele usar como referencia para detectar comportamientos inusuales o anomalías. Basándonos en las compras típicas de un determinado cliente, podemos detectar si un nuevo cargo en su tarjeta de crédito se ajusta a ese patrón. Podemos crear asignarle un “score” o grado de sospecha de fraude, y lanzar una alerta cuando se supere cierto umbral.
- Predicción de vínculos: intenta predecir conexiones entre elementos. Por ejemplo, entre miembros de una red social o profesional. Te hacen sugerencias como:
“María y tú tenéis 10 amigos en común. ¿No deberíais ser amigas?»
“Personas que probablemente conozcas”
-
Reducción de datos: a veces es necesario reducir el volumen de datos de trabajo. Por ejemplo, en lugar de trabajar con una enorme base de datos de preferencias de consumo de películas, trabajar con una versión reducida de ellos, como sería el “género” de la película, más que la película concreta. Siempre que se realiza una reducción de datos se pierde información. Lo importante es llegar a una solución de compromiso entre la pérdida de información y la mejora de los Insights.
-
Modelado Causal: estas tareas lo que buscan es detectar la influencia de unos hechos sobre otros. Por ejemplo, si se incrementan las ventas en un grupo de clientes a los que nos hemos dirigido con una campaña de marketing:
¿Se incrementaron las ventas gracias a la campaña o simplemente el modelo predictivo detectó bien a los clientes que hubieran comprado de cualquier forma?
En este tipo de tareas es muy importante definir bien las condiciones que se tienen que dar para poder hacer esa conclusión causal.
Por tanto, cuando queremos abordar con ML un problema de negocio, como el típico ejemplo de “fuga de clientes” (el famoso churn), lo que queremos averiguar es qué clientes están más o menos predispuestos a dejar de serlo.
Podríamos abordarlo como un problema de clasificación, o clustering, incluso como un problema de regresión. Según cómo definamos el problema, trabajaremos con una familia de algoritmos u otra.
Si quieres seguir aprendiendo sobre Machine Learning, no te pierdas el post sobre los tipos de error.





