
En el mundo de los negocios, la ciencia y la tecnología, se habla mucho de estos tres conceptos, pero muchas veces no tenemos una idea clara de su significado, sus relaciones y sus límites.
Este es el primer post de una nueva “miniserie” del blog del LUCA, que en este caso, tratará sobre Machine Learning. Introduciremos los conceptos básicos de forma clara y sencilla, pero también nos pondremos manos a la obra con ejemplos reales.
En este post definiremos el concepto de Machine Learning y sus diferencias respecto a los conceptos de Inteligencia Artificial y Deep Learning.


¿Qué es IA?
El concepto de Inteligencia Artificial no es nuevo. Lleva dando vueltas por el mundo por lo menos desde los años 50, en que Alan Turing creó su famoso test para determinar si un ordenador posee inteligencia real. Poco después, en 1956 tuvo lugar en Dartmouth la primera Conferencia de Inteligencia Artificial, que supuso el pistoletazo de salida oficial para este nuevo campo de la ciencia.
En esta conferencia se planteó la conjetura de que tanto el aprendizaje, como la inteligencia humana, en todos sus aspectos, podían ser descritos con el detalle suficiente para poder ser reproducidos por una computadora.
Porque la idea fundamental en que se basa la Inteligencia Artificial es en conseguir que una computadora resuelva un problema complejo como lo haría un humano. En ocasiones, esos problemas “complejos” para una persona no lo son tanto. Por ejemplo, para una persona, resulta muy sencillo como:
- Identificar un gato en una foto.
- Descifrar un texto borroso, o en el que falta alguna letra.
- Identificar un sonido.
- Priorizar tareas.
- Conducir un coche.
- Jugar a un juego y ganar (incluso ganar al campeón mundial de ajedrez, aunque no sea un buen ejemplo del algo “muy sencillo” para cualquier persona).
- O hacer algo creativo como escribir un poema o resumir una idea con un dibujo.
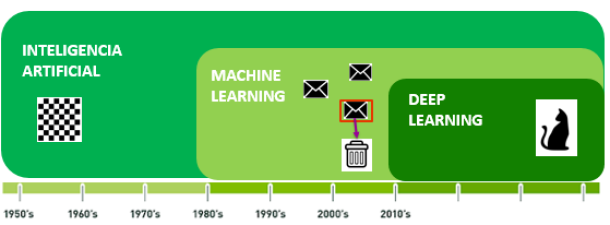
Desde los años 50 distintas áreas de la IA, primero el ML y luego el DL han supuesto grandes disrupciones.
¿Cómo resuelve estas tareas una persona?
Para poder emular el proceso, una computadora debe sumar a sus capacidades en cuanto a potencia de cálculo, velocidad de procesamiento y capacidad de almacenamiento de datos, otras nuevas que permitan imitar el razonamiento de la mente humana de forma funcional. Así, necesita poder:
- Captar información del entorno: Percepción. Los humanos, nos comunicamos con nuestro entorno por medio de nuestros sentidos. Hoy día existen multitud de sensores de todo tipo que pueden realizar esta función, recogiendo información del entorno y enviándola para su procesamiento en la computadora. Incluso pueden superar a los “sentidos humanos”, ya que no están sometidos a los límites de nuestra biología.
- Comprender el lenguaje natural (Natural Language Processing). Interpretar el lenguaje hablado y escrito. Comprender el significado de una frase, entender distintos acentos. Ésta es una tarea difícil, ya que el significado de una frase puede variar mucho según su contexto.
- Representar el conocimiento. Esta IA capaz de percibir personas, objetos, conceptos, palabras, símbolos matemáticos etc., necesita poder representar ese conocimiento en su “cerebro artificial”.
- También necesita la capacidad de razonar. Ser capaz de conectar todo ese conocimiento, datos y conceptos, para poder resolver problemas usando la lógica. Por ejemplo, una máquina de ajedrez detecta los movimientos de las fichas sobre el tablero, y aplicando las reglas del ajedrez a los datos que ha recogido, decide la mejor jugada.
– Ser capaz de planificar y desplazarse. Para parecerse realmente a un humano, no basta con pensar como un humano. Nuestra IA debe ser capaz de moverse en un mundo tridimensional, eligiendo la ruta óptima. Esto es lo que hacen ya lo vehículos autónomos, pero deben hacerlo bien, porque en este caso, los errores cuestan vidas.
¿Qué factores han ayudado a impulsar el desarrollo de la IA?
A lo largo de las últimas décadas aquello que en un principio parecía una utopía ha ido haciéndose realidad. Son varios los factores que han ayudado a impulsar el desarrollo de la IA.
Uno de los factores que más ha contribuido al avance de la IA, además de la inversión de las grandes tecnológicas en I+D, ha sido la ley de Moore. La ley de Moore no es una ley en el sentido científico, sino más bien una observación. En 1965 Gordon Moore predijo el incremento continuado de la complejidad de los circuitos integrados, (medida por el número de transistores contenidos en un chip de computador), al tiempo que se reducía su coste.
Esto permitió a la entonces naciente industria de semiconductores crear el microprocesador (en 1971) y otros circuitos integrados que en principio se aplicaban a las computadoras, pero hoy en día podemos encontrar en cualquier dispositivo (móviles, televisores, vehículos) o incluso en seres vivos (como los chips de identificación implantados en animales). Gracias a esto, las aplicaciones de Inteligencia Artificial forman hoy en día parte de nuestra vida cotidiana.
Otro de los factores que ha impulsado en gran medida el desarrollo de la Inteligencia Artificial (IA) han sido las tecnologías Big Data. En 2012, Google dio la campanada cuando demostró ser capaz de identificar la imagen de un gato en una foto con un 75% de precisión. Para lograrlo, utilizó redes neuronales a las que entrenó con un corpus de 10 millones de vídeos de YouTube. Evidentemente, esto no hubiera sido posible sin recurrir al Big Data.
¿Y qué tipos de IA hay?
Básicamente, hay dos tipos de Inteligencia Artificial. La conocida como “débil o estrecha” (narrow/weak AI) se caracteriza por estar “especializada” en una tarea concreta. Por ejemplo, ganar a un juego. Deep Blue, creada por IBM ganó a en 1996 al gran maestro de ajedrez Gary Kasparov. En 2016, DeepMind’s AlphaGo, creada por Google, venció al el jugador profesional de Go surcoreano Lee Sedol.
Los asistentes digitales como Siri y Cortana también son ejemplos de este tipo de IA. Pueden darnos la predicción meteorológica, o recomendarnos una ruta alternativa para ir al trabajo, pero no leer nuestros mensajes y borrar los que no son importantes. No pueden ir más allá de aquello para lo que originalmente fueron programados.
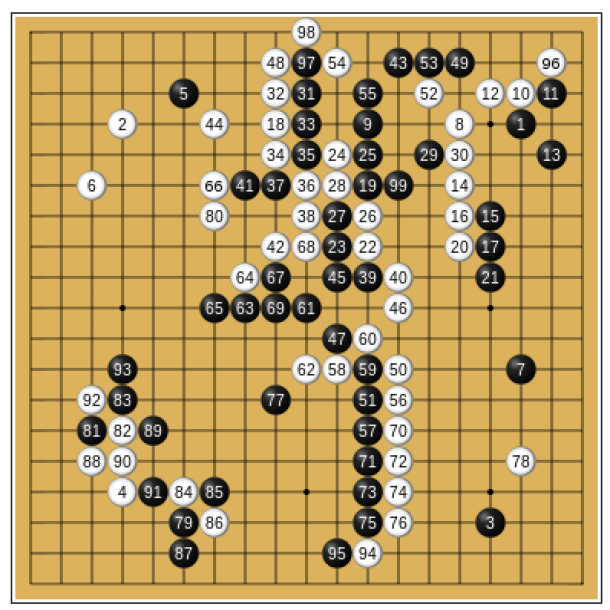
Primeras 99 jugadas de la partida de AlphaGo vs Lee Sedol.
La Inteligencia Artificial “fuerte” (strong AI) sí nos lleva al mundo de la ciencia ficción. Un excelente ejemplo sería Samatha, asistente personal del protagonista Theodore Twombly en la película Her. Samantha es la asistente personal perfecta porque puede aprender cosas nuevas y modificar su código base. Puede organizar tu correo, tus reuniones, ganarte al ajedrez y escribir la lista de la compra. Es inteligente, empática, adaptativa…
Ya tenemos una idea más clara de lo que es la Inteligencia Artificial. Una de sus áreas de aplicación más conocidas es la robótica, pero tiene también importantes aplicaciones en los campos de la medicina, la educación, el entretenimiento, la gestión de la información, las matemáticas, las aplicaciones militares, diseño urbano, arquitectura etc.
¿Qué es el Machine Learning (ML)?
Los primeros programas basados en IA, como Deep Blue, se basaban en reglas y eran programados por una persona. Machine Learning o Aprendizaje Automático es una rama de la Inteligencia Artificial que empezó a cobrar importancia a partir de los años 80. Es una forma de IA que ya no depende de unas reglas y un programador, sino que la computadora puede establecer sus propias reglas y aprender por sí misma.
DeepMind de Google, que consiguió ganar al campeón del mundo de Go, lo hizo aplicando técnicas de aprendizaje automático y entrenándose con una gran base de datos que recogía jugadas de expertos en el juego. Por tanto, es un buen ejemplo de aplicación de ML.
Los sistemas de ML trabajan sobre grandes volúmenes de datos, identifican patrones de comportamiento y, basándose en ellos, son capaces de predecir comportamientos futuros. De esa forma son capaces de identificar a una persona por su cara, comprender un discurso, distinguir un objeto en una imagen, hacer traducciones y muchas otras cosas más. Es la herramienta más potente en el kit de IA para los negocios.
Por ello, las grandes empresas tecnológicas como Amazon, Baidu, Google, IBM, Microsoft y otras más, ofrecen sus propias plataformas de “ML for business”.
¿Y cómo aprenden las máquinas?
El aprendizaje automático se produce por medio de algoritmos. Un algoritmo no es más que una serie de pasos ordenados que se dan para realizar una tarea. El objetivo del ML es crear un modelo que nos permita resolver una tarea dada. Luego se entrena el modelo usando gran cantidad de datos. (En los próximos post de la serie lo analizaremos con más detalle). El modelo aprende de estos datos y es capaz de hacer predicciones.
Según la tarea que se quiera realizar, será más adecuado trabajar con un algoritmo u otro. Los modelos que obtenemos dependen del tipo de algoritmo elegido. Así, podemos trabajar con modelos geométricos, modelos probabilísticos, o modelos lógicos. Por ejemplo, uno de los modelos lógicos más conocidos es el basado en el algoritmo árbol de decisión, que también veremos con detalle más adelante.
Pero como «tráiler» os remito a este clásico ejemplo de aprendizaje basado en árboles de decisión, sobre las probabilidades de supervivencia de un pasajero del Titanic, según su sexo, su edad y si tenían hermanos/as a bordo. Se trata de resolver una tarea de clasificación, de asignar a cada individuo una etiqueta «died»(murió) o «survived» (sobrevivió), basándose en las respuestas a las preguntas que se plantean en cada uno de los nodos.
Árbol de Decisión de los supervivientes del Titanic.
¿Qué es el Aprendizaje Profundo o Deep Learning?
Uno de los algoritmos de ML que más expectación despierta, son las redes neuronales, una técnica que se inspira en el funcionamiento de las neuronas de nuestro cerebro. Se basan en una idea sencilla: dados unos parámetros hay una forma de combinarlos para predecir un cierto resultado. Por ejemplo, sabiendo los píxeles de una imagen habrá una forma de saber qué número hay escrito.
Los datos de entrada van pasando secuencialmente por distintas «capas» en las que se aplican una serie de reglas de aprendizaje moduladas por una función peso. Tras pasar por la última capa, los resultados se comparan con el resultado «correcto», y se van ajustando los parámetros (dados por las funciones «peso»).
Aunque los algoritmos y en general el proceso de aprendizaje son complejos, una vez la red ha aprendido, puede congelar sus pesos y funcionar en modo recuerdo o ejecución. Google usa este tipo de algoritmos, por ejemplo, para las búsquedas por imagen.
No existe una definición única de lo que es Deep Learning. En general, cuando hablamos de Deep Learning hablamos de una clase de algoritmos de Machine Learning basados en redes neuronales que, como hemos visto, se caracterizan por un procesamiento de los datos en cascada. La señal de entrada se va propagando por las distintas capas, y en cada una de ellas se somete a una transformación no lineal que va extrayendo y transformando las variables según determinados parámetros (pesos o umbrales).
No hay un límite establecido para el número de capas que debe tener una red neuronal para considerarse Deep Learning. Sin embargo, se considera que el aprendizaje profundo surgió en los años 80, a partir de un modelo neuronal de entre 5 o 6 capas, el neocognitrón, creado por el investigador japonés Kunihiki Fukushima. Las redes neuronales son muy efectivas en la identificación de patrones.
Un ejemplo muy llamativo de aplicación de Deep Learning es el proyecto conjunto de Google con las Universidades de Stanford y Massachusetts para mejorar las técnicas de procesamiento de lenguaje natural de un tipo de IA llamada Modelo de Lenguaje de Redes Neuronales Recurrentes (Recurrent Neural Network Language Model RNNLM).
Se usa para traducción automática y creación de subtítulos, entre otras cosas. Básicamente, va construyendo frases palabra a palabra, basándose en la palabra anterior. Incluso, puede llegar a escribir poemas.

Poema escrito por una IA de Google después de entrenarse con miles de novelas románticas.
Una vez puestos en contexto, os invitamos a aprender más sobre en los próximos post de esta miniserie sobre el tema.
¡No te los pierdas!
Machine Learning






