
Las investigaciones acerca de Inteligencia Artificial han avanzado mucho, sobre todo en lo que a resultados cognitivos se refiere.
PARTE I
La Inteligencia Artificial moderna es capaz de conseguir resultados cognitivos que parecían completamente inalcanzables hace solo unos pocos años. Es cierto que estamos hablando de IA de dominio (tareas que involucran solo un pequeño subconjunto de capacidades humanas) – la Inteligencia Artificial general está todavía muy lejana. Pero en esas tareas de nicho estamos observando avances espectaculares.
Los resultados más llamativos están en el ámbito de la percepción: percepción visual (reconocimiento en imágenes, que en tareas tales como reconocimiento masivo de objetos está consiguiendo rendimiento a nivel humano) o percepción de audio (el reconocimiento de lenguaje también consigue una calidad de acierto muy alta). Pero otros sectores también han conseguido grandes titulares, como cuando AlphaGo de Google venció a campeones de Go. Hay incluso incursiones iniciales en ámbitos “artísticos”, tales como estilos pictóricos o composición musical.


Muchos de esos avances están muy relacionados con desarrollos en un área concreta de Machine Learning – Aprendizaje Profundo (Deep Learning): aprendizaje estadístico realizado por redes neuronales con multitud de capas. El aprendizaje profundo está consiguiendo resultados impresionantes en multitud de áreas gracias a su versatilidad y las capacidades de las redes modernas de ser entrenadas de forma eficiente. Pero hay un inconveniente: para obtener ese rendimiento mágico, una red de aprendizaje profundo generalmente necesita ser entrenada con cantidades enormes de datos.
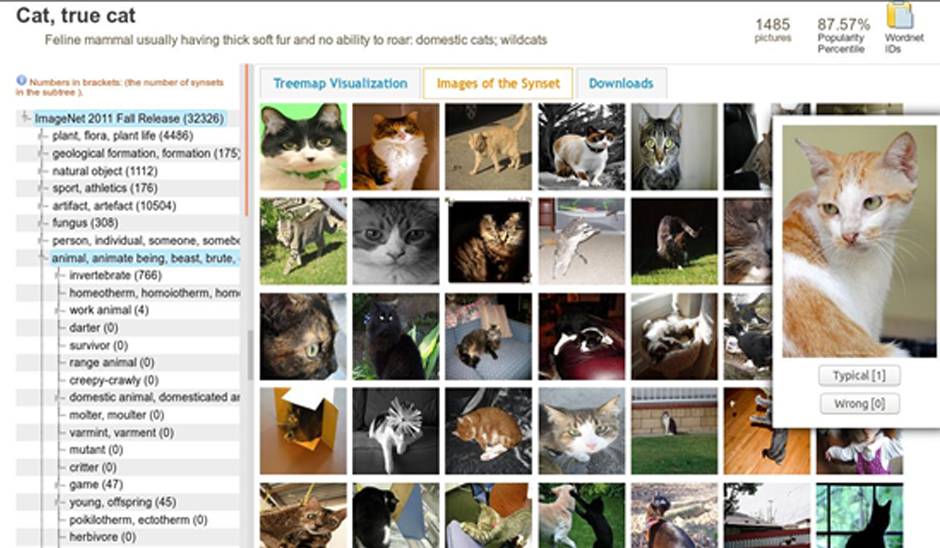
Un ejemplo típico es ImageNet, la base de datos de imágenes usada frecuentemente para entrenar clasificadores de Deep Learning en reconocimiento de objetos. ImageNet es grande: contiene más de 14 millones de imágenes. Están distribuidas en muchas clases: hay cerca de 22.000 clases de imágenes distintas (cada clase son las imágenes que contienen instancias relevantes de un objeto dado). Si tenemos el objetivo de, por ejemplo, reconocer gatos en imágenes, podríamos recolectar las imágenes de gatos en ImageNet y entrenar una red neuronal profunda con ellas (usando también una cantidad sustancial de imágenes que no contienen gatos). ¿Con cuántas imágenes contaríamos? Incluyendo las subcategorías (como gato siamés, gato de Angora, etc) hay 22.387 imágenes con gatos en ImageNet. Desde luego son un montón de datos.
La IA moderna está muy centrada en reconocimiento estadístico de patrones, y eso supone una enorme diferencia con la IA antigua (“clásica”), que era en gran parte simbólica. Al comienzo del desarrollo de la Inteligencia Artificial se tenía el concepto de que había que moverse en el ámbito de lógica y razonamiento, usando una estructura que se ha denominado GOFAI (Good-Old Artificial Intelligence). Se trataba de establecer reglas y razonar sobre ellas, tratando de emular los niveles superiores del pensamiento humano. Esto no terminó de funcionar. Para tareas de percepción GOFAI falló estrepitosamente, al ser incapaz de acomodar la gigantesca variabilidad del mundo real, lleno de instancias ruidosas no susceptibles de razonamiento preciso.
Hoy en día se considera que las tareas relacionadas con percepción (hacer que el mundo que nos rodea tenga sentido) se resuelven de forma mucho más efectiva con aprendizaje automático, entrenando sistemas con ejemplos reales del mundo. Pero ¿por qué necesitamos tantos? ¿Necesitan los humanos tantos ejemplos para reconocer cosas?
No tengo datos a mano, pero parece poco probable que un niño necesite ver 22.000 ejemplos etiquetados de gatos (es decir, que sus padres y profesores le muestren 22.000 gatos y se los señalen como gatos) antes de poder reconocer uno. Por supuesto, dado que frecuentemente cada gato se le mostrará al niño no como una imagen estática sino como un animal vivo, el niño puede verlo desde distintos ángulos y en movimiento; eso ayuda a la identificación. Pero aún así. Los seres humanos parecen necesitar muchos menos ejemplos para poder reconocer objetos. Sin embargo esta comparación no es justa.
Una red neuronal profunda preparada para identificación visual arranca en un estado limpio. Fijamos su topología (número y tipo de capas de neuronas, funciones de activación, etc) y el proceso de entrenamiento que vamos a seguir (mini-batches, dropout, momentum, etc). Pero los parámetros de la red (los pesos de los enlaces, de los que una red grande puede tener millones) vienen sin inicializar, o con inicialización aleatoria.
A partir de ese momento inicial, durante el entrenamiento a la red se le muestran todos los datos convenientemente etiquetados (incluidos nuestros 22.000 gatos) muchas veces. Al final de cada ciclo de entrenamiento el sistema ha aprendido de los ejemplos que ha visto y (generalmente) mejora su tasa de reconocimiento, paso a paso, hasta que alcanza su (impresionante) éxito final.
Un cerebro humano, sin embargo, no tiene ni mucho menos un estado limpio.
En vez de eso, viene preconfigurado con un montón de “cableado”. Este cableado viene determinado por el genoma humano, que es el que contiene las instrucciones para construir el cerebro. Esas instrucciones han sido moldeadas por millones de años de selección natural: la evolución ha formado la estructura neuronal base del cerebro que nos ha hecho más preparados para sobrevivir, entre ella la que puede equipararse a una enorme cantidad de “ciclos de entrenamiento” para nuestros circuitos neuronales. No nacemos con “pesos aleatorios” en el cerebro, sino con estructuras ya bien configuradas para tareas perceptuales. Entre ellas, la identificación de animales felinos. Una habilidad presumiblemente muy útil para la supervivencia, luego un buen rasgo para ser adquirido vía selección natural.

En este sentido podemos argumentar que el cerebro humano ha sido pre-entrenado por la evolución (aunque luego durante el aprendizaje de la infancia siga aprendiendo). Es decir, nuestras conexiones neuronales tienen una gran ventaja adquirida sobre los sistemas de IA actuales, que estos tienen que equilibrar a base de usar multitud de ejemplos. En la segunda parte hablaremos de algunas técnicas para (en cierto modo) sobrellevar mejor este apetito desmesurado de datos de los sistemas de aprendizaje profundo.
Parte II
La IA moderna puede conseguir la impresionante calidad en tareas de percepción y reconocimiento mencionada en la parte I gracias a avances en varias áreas: mejoras algorítmicas (especialmente en el área de Deep Learning), incremento de la capacidad de computación (computación en nube, GPUs) y, muy particularmente, Internet.
Internet es lo que hizo posible conseguir recolectar los 14 millones de ejemplos de imágenes disponibles en ImageNet mencionados en la parte anterior. En el caso de aprendizaje supervisado, proporciona los millones de ejemplos anotados necesarios para que los algoritmos aprendan de ellos. Da una nueva perspectiva a la cita de Newton “estar sentado a hombros de gigantes”, transformándola en “estar sentado sobre millones de enanos”.
Otro ejemplo famoso es el caso de Alpha Go. ¿Cómo consiguió batir a campeones mundiales de Go? Entrenando con muchos más ejemplos de partidas que los maestros de Go podrían jugar durante toda su vida. Usó 30 millones de movimientos de 160.000 partidas reales de una base de datos. Luego mejoró mediante el uso de aprendizaje por refuerzo (una variante de aprendizaje automático que permite a los sistemas aprender optimizando una función objetivo, en este caso ganar el juego) jugando contra sí mismo con decenas de millones de posiciones.
Su sucesor, AlphaGo Zero (o el más reciente AlphaZero, que también puede jugar al ajedrez y al shogi) parece haber vencido esa restricción: aprende sin datos. Sólo se le proporcionan las reglas del juego, y a partir de ahí usa aprendizaje por refuerzo para mejorar sus habilidades. Sin embargo, la forma que tiene de funcionar es jugando contra sí mismo: AlphaGo Zero jugó casi 5 millones de partidas contra sí mismo durante su entrenamiento inicial. Se puede argumentar que esto no cambia el planteamiento: lo que sus creadores han conseguido es una forma astuta de conseguir datos sintéticos (las partidas de AlphaGo Zero contra sí mismo) para entrenar, pero la cantidad de datos necesaria sigue siendo enorme. Sigue sin haber nada mejor que la práctica.
Pero aunque recolectar grandes volúmenes de datos es una de las razones de los recientes avances en aprendizaje automático, no puede llevarnos hasta el infinito: hay un límite en el volumen de datos de entrenamiento que podemos recolectar. Y para algunas tareas es intrínsecamente difícil conseguir suficientes buenos ejemplos. Un modo en el que las personas solucionan este problema es usando aprendizaje por transferencia (transfer learning), por el que el conocimiento aprendido en una tarea, dominio o clase de datos puede usarse en otro contexto.

Probablemente no hayas visto nunca una babirusa (Babyrousa celebensis), así que no tienes entrenamiento específico para reconocerla. Sin embargo sí tenemos entrenamiento genérico para reconocer formas y partes de animales, así que simplemente viendo (y recordando) solo esta imagen, la próxima vez que veas otra babirusa probablemente la reconocerás. Agradéceselo al aprendizaje por transferencia.
Los sistemas de Deep Learning también pueden usar aprendizaje por transferencia. Un uso muy típico es emplear una red pre-entrenada para una tarea distinta. Por ejemplo, una red profunda entrenada para reconocimiento de imagen típicamente comienza con unas capas convolucionales, que transforman los datos de entrada (imagen) en un espacio latente de nivel superior (una . Sucesivas capas realizan la tarea final deseada (clasificación).
Podemos tomar esas capas ya entrenadas, aprovechando la representación aprendida, apilar nuevas capas sobre ellas, y reentrenar el resultado para una nueva tarea. Como una gran parte de la nueva red ya ha sido pre-entrenada, si suponemos que ese pre-entrenamiento es válido para la nueva tarea, el tiempo final de entrenamiento se puede reducir enormemente y el volumen de datos de entrenamiento para conseguir buenos resultados será mucho menor. Podemos por tanto asumir que hemos realizado aprendizaje por transferencia desde la red original hacia la nueva red.
Este procedimiento (usar una red pre-entrenada para una nueva tarea) está ya establecido como proceso estándar para clasificación de imágenes, aunque todavía requiere datos de cierto tamaño para la nueva tarea. Estos requisitos podrían ser aliviados usando técnicas tales como meta-learning, en el que el sistema aprende cuál es el mejor procedimiento para aprender la nueva tarea.
Existe también una versión más extrema de aprendizaje por transferencia llamado zero-shot learning (aprendizaje sin datos). En esta modalidad es posible identificar clases sin haber visto nunca ni un solo ejemplo de ellas. ¿Cómo podemos conseguir algo así? Puede hacerse usando transferencia de dominio (una variante de aprendizaje por transferencia). Si digo que “el lobo de crin o aguará guazú es un animal similar a un zorro pero con las patas inusualmente largas” entonces sería posible identificar cuál de los tres animales en la siguiente figura es un lobo de crin sin haber visto nunca ninguno.
 Lobo de Crin. Fuente: imgur
Lobo de Crin. Fuente: imgur
Hay también técnicas de aprendizaje automático desarrolladas para realizar zero-shot learning. Algunas emplean el mismo proceso de transferencia de dominio: mapean características visuales de objetos y representaciones semánticas de palabras (extraídas de corpus de texto), de forma que un sistema entrenado con perros, peces, ranas, etc pero no con gatos pueda encontrar ejemplos de gatos evaluando cómo los gatos se relacionan con otros términos en el dominio semántico, y mapeándolo al dominio visual. Lo que no resulta tan distinto de cómo lo haría una persona.
En resumen, los procesos genéricos usados por el aprendizaje automático moderno pueden estar usando características no demasiado alejadas de lo que los cerebros humanos hacen. Y si vamos más allá del aprendizaje supervisado estándar, hay un creciente número de herramientas y procesos, tales como aprendizaje por transferencia, zero-shot learning, aprendizaje por refuerzo, aprendizaje no supervisado o nuevas arquitecturas, que pueden incrementar sus capacidades para identificar patrones y entidades en la realidad que nos rodea, que es una gran parte (aunque por supuesto no toda) de nuestro equipaje cognitivo como humanos. Al menos en lo que concierne a la percepción.






