
Un algoritmo de aprendizaje es capaz de rastrear los usuarios potenciales más predispuestos a viralizar el contenido de tus tuits para llegar a un mayor número de personas
Miles de empresas y profesionales utilizan a diario redes sociales como Twitter para generar campañas virales con las que difundir su marca, además de promocionar sus servicios y productos mediante mecanismos de viralización hacia las redes de contactos de sus seguidores. Pues bien, un algoritmo desarrollado por un grupo de investigadores podría aumentar el número de retuits hasta en seis veces, mediante la detección de usuarios con más probabilidades de difundir estos micromensajes para llegar al mayor número de usuarios posibles.
¿Cómo conseguir que se retuitee información?
Este es el reto al que se enfrentan cada día muchos profesionales del Social Media, pero Kyumin Lee, investigador de la Universidad Estatal de Utah en Logan, junto con varios compañeros del centro de investigación Almaden de IBM, San José –EEUU–, han dado con la solución mediante un algoritmo matemático.


Tras un estudio de las características de los usuarios de Twitter, los investigadores han determinado que existen perfiles más propensos que otros a difundir ciertos tipos de mensajes a otros usuarios, según determinados momentos del día. Los trabajos de investigación se han centrado en identificar a los usuarios más proclives a retuitear los micromensajes para dirigirse a ellos en el momento del día en el que posiblemente sean más activos y eficaces.
Con esta nueva técnica de rastreo de perfiles afines a cierto tipo de información, los investigadores aseguran haber sido capaces de mejorar el índice de viralidad de mensajes vía Twitter en hasta un 680%. Una cifra nada despreciable que colmaría los objetivos de las estrategias de comunicación de más de una empresa o la reputación personal de miles de profesionales que tratan de difundir su trabajo a través de las redes sociales.
El método
Desde el punto de vista teórico, las investigaciones previas se centraron en analizar perfiles de Twitter en busca de patrones de comportamiento que ofrecieran pistas sobre las tendencias a retuitear cierto tipo de información. Para optimizar la tasa de retuiteo se registró información pública de cada perfil, número de seguidores, personas a las que siguen, momento del día de mayor actividad, así como sus últimos 200 tuits y retuits realizados.
Con todos estos datos, Lee y su equipo utilizaron un algoritmo de aprendizaje automático capaz de establecer correlaciones que pudieran determinar la probabilidad de retuitear cierta información. Para luego determinar que personas son más proclives a viralizar el contenido de los micromensajes y enviarles los tuits.
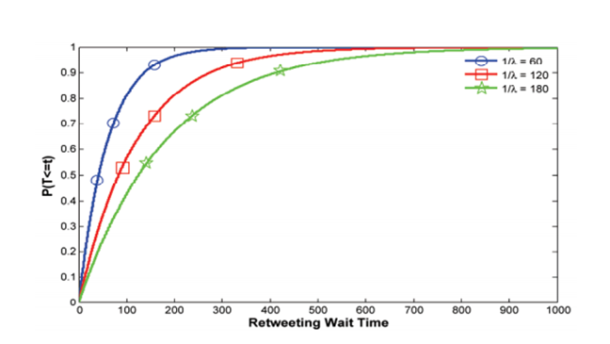
La práctica
Para poner en práctica el experimento y comprobar la eficacia del algoritmo de aprendizaje, se midió la capacidad de respuesta de los usuarios seleccionados en base a dos tipos de información que estaban de actualidad en el momento del estudio: noticias locales sobre San Francisco y tuits sobre la gripe aviar. Previamente crearon varias cuentas de Twitter con cierto número de seguidores para retuitear dicha información y a continuación seleccionaron a las personas que recibían dichos tuits.
Los resultados obtenidos muestran que el algoritmo de aprendizaje capaz de captar usuarios propensos a retuitear un tema concreto es sorprendentemente eficaz. El índice de retuiteo de información local a las personas identificadas por el algoritmo alcanzó el 19,3% en los momentos del día donde se registró una mayor actividad de dichos usuarios, mientras que en los tuits sobre la gripe aviar llegaron al 19,7%. Es decir, una mejora de la tasa de retuiteo de hasta un 600% según los cálculos realizados.
A la vista de los resultados, el algoritmo podría resultar tremendamente útil para los expertos en estrategias de marketing, medios de comunicación o incluso para un sector bastante tocado últimamente como el de la política. En cambio, no ha trascendido hasta el momento ningún plan para comercializar dicha aplicación por parte de sus responsables.
Imágenes y gráficos | vía Flickr –Garrett Heath y Marc_Smith– y Cornell University Library






